If you’re working with Claude on a daily basis – whether that’s through the API, Claude Code, or just keeping up with what Anthropic is doing – you know how hard it is to stay on top of things. Model releases, API changes, Claude Code updates, community discoveries. It’s spread across a handful of sites and there’s no single place that pulls it all together.
So I built one.
What is claude-pulse?
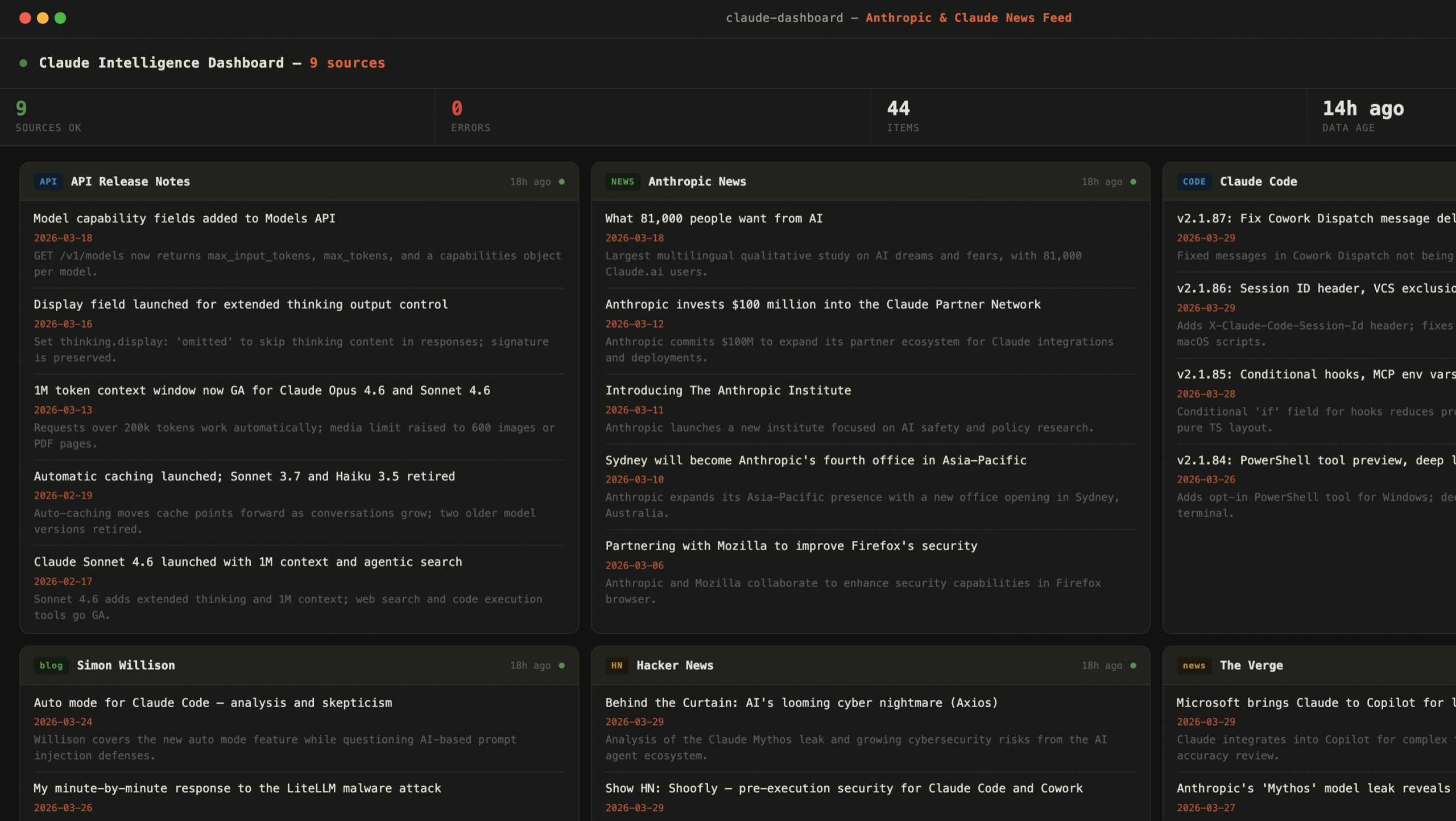
claude-pulse is a static HTML dashboard that aggregates the latest headlines and updates from 9 sources I care about:
- Anthropic News – first-party announcements and research
- API Release Notes – developer-facing platform changes
- Claude Code Changelog – updates to the coding tool I use every day
- Claude Blog – product and feature stories from Anthropic
- Anthropic Engineering – technical deep-dives from the engineering team
- The Verge – fast external coverage of anything Anthropic-adjacent
- Hacker News – community signal, often the fastest way to hear about something breaking or something impressive
- Simon Willison’s blog – the best independent technical commentary on Claude releases, bar none
- r/ClaudeAI – community discussion, bug discoveries, workarounds
Each source gets its own card. Each card shows the latest headlines with dates and short summaries. Sources that couldn’t be fetched automatically sort to the bottom so healthy cards stay up front.
Live Preview
Updated twice daily – view full dashboard
How it works
This is where it gets a bit meta: the dashboard is generated by Claude Code.
A local agent runs twice a day, fetches all 9 sources using a custom /notebooklm skill, structures the results as JSON, and injects them directly into an HTML template as an inline script constant. The output is a fully self-contained index.html – no backend, no API calls at runtime, no external dependencies. Just a file.
That file gets pushed to a GitHub repository. GitHub Pages serves it. Done.
Claude Code + /notebooklm → index.html → git push → GitHub Pages
The dashboard itself is vanilla HTML and JavaScript. Cards are draggable so you can arrange them however you like, and the order persists across page reloads via localStorage. The whole thing opens fine as a local file too.
What I learned building it
A few things stood out during the build:
Static is underrated. There’s something satisfying about a monitoring tool that has zero runtime infrastructure. No server to maintain, no database, no API keys in production. The complexity lives entirely in the generation step, which runs on my machine on a schedule I control.
Claude Code as a data agent works well for this kind of task. Fetching structured content from a mix of HTML pages, JSON APIs, and community sites in a single coordinated run – that’s exactly the kind of heterogeneous task where an agentic approach beats writing custom scrapers for each source.
Token cost is a real design constraint. When you’re running something repeatedly on a schedule, token consumption stops being an abstract concern and becomes a practical one. The /notebooklm skill made the difference between something I’d run hourly and something I’d run once and forget about.
It’s live
The dashboard is published at seriousbydesign.github.io/claude-pulse and the repo is public. If you work with Claude daily and want a single place to catch releases, changelogs, and community signal without checking five different sites – this is it.
Fair warning: running it yourself requires a compatible Claude Code skill for fetching structured content – the README covers what the interface needs to look like. There are a some /notebooklm skills already out in the wild that should work as a drop-in. Curious whether they do. If you give it a try, let me know how it goes. I’m planning to release the skill I use separately, once the backlog is emptied.
Update — April 4, 2026
Since publishing this I’ve done a proper optimisation pass on the pipeline, and the numbers improved more than I expected.
The main change: all 9 source fetches now go out simultaneously. Add Claude Haiku as the model for the orchestration step and a full run now takes about 3 minutes and costs around 4% of a Claude Pro session limit. It was 8 minutes and ~20% before.
There was one unexpected discovery along the way. I tested whether NotebookLM could return structured JSON directly – schema and all – rather than prose that Claude Code then has to parse. It can. Each fetch now returns a source object ready to drop into data.json. Claude Code coordinates and assembles; it doesn’t interpret. That’s what made the token reduction possible.
The pipeline diagram from the original post now has one extra step:
Claude Code + /notebooklm → data.json → index.html → git push → GitHub PagesTagged as v1.0.